Role of Databases in GenAI Applications

Introduction to Generative AI
Generative AI (GenAI) represents a transformative leap in artificial intelligence, enabling machines to create human-like content, generate insights, and enhance decision-making across various domains. Unlike traditional AI models that classify or predict based on predefined patterns, GenAI leverages advanced machine learning techniques, such as deep learning and large language models (LLMs), to generate text, images, code, audio, and more. These AI models, trained on massive datasets, can understand context, generate creative outputs, automate workflows, and drive innovation in industries such as healthcare, finance, customer support, and software development. With advancements in Transformer architectures, Reinforcement Learning with Human Feedback (RLHF), and multimodal AI, Generative AI is reshaping the way businesses operate, unlocking new possibilities for automation and personalization.
Value Proposition of Generative AI Applications
Generative AI applications deliver substantial business value by enhancing efficiency, creativity, and decision-making. Below are some key value propositions:
Enhanced Productivity & Automation
- Automates repetitive tasks like document generation, summarization, and code completion, reducing manual effort and improving efficiency.
- Enables self-service customer support with AI-powered chatbots that provide contextual and natural interactions.
Personalized User Experience
- Powers hyper-personalization by generating tailored content, recommendations, and responses based on user preferences and context.
- Enhances marketing efforts with AI-generated ad copies, email campaigns, and personalized product recommendations.
Intelligent Decision-Making
- Helps in real-time data analysis and insights extraction for better decision-making in finance, healthcare, and operations.
- Improves fraud detection, risk analysis, and compliance monitoring by analyzing vast amounts of structured and unstructured data.
Creativity & Content Generation
- Generates high-quality content, including articles, product descriptions, scripts, and creative writing for media and marketing.
- Assists in design, music, and video generation, reducing creative bottlenecks and accelerating production cycles.
Cost Optimization & Scalability
- Reduces costs associated with manual content creation, customer support, and software development by automating key processes.
- Scales seamlessly across global operations, enabling faster market expansion and localized content generation.
Democratization of AI & Innovation
- Enables non-technical users to leverage AI-driven tools for content creation, analysis, and automation.
- Empowers developers, researchers, and enterprises to build new AI-driven applications without extensive AI expertise.
From Bits to Brains: Why the Right Database Matters in GenAI
In many GenAI applications, there’s a common misconception that only a vector database is needed particularly for semantic search and embedding management. However, different parts of the application often require specialized storage solutions. For conversational context, key-value or document databases can handle unstructured chat logs with high throughput. For situational context, relational databases or data Lakehouse are indispensable for structured data, user profiles, and operational metrics. Vector databases do play a pivotal role in semantic context, but relying on them exclusively can lead to performance bottlenecks, data inconsistencies, and an incomplete view of user interactions. By matching each data type to the most appropriate database technology, GenAI solutions can deliver faster, more accurate, and contextually rich responses ensuring the true potential of AI-driven applications is fully realized.
In GenAI applications, real-time data processing demands databases that can handle rapid queries and large-scale ingestion without bottlenecks. Traditional systems often struggle with the high throughput required to train and deploy AI models, making scalability and low latency critical. Furthermore, these models frequently rely on complex and unstructured data formats, necessitating flexible schemas and advanced indexing capabilities for efficient retrieval. Continuous model updates also mean databases must accommodate concurrent writes and version control to ensure model integrity. Ultimately, selecting a wrong database can lead to performance degradation, compromised accuracy, and diminished overall effectiveness of GenAI solutions.
Role of Databases in Generative AI Applications
Databases play a critical role in Generative AI (GenAI) applications, ensuring efficient data storage, retrieval, and contextual augmentation for AI-driven responses. When a user interacts with a GenAI-powered system, the application relies on multiple databases to fetch historical context, enrich responses with enterprise knowledge, and enhance overall accuracy.
In the user’s critical path, databases contribute to key stages of the workflow, enabling AI models to make informed decisions by leveraging structured and unstructured data. When an end-user interacts with a Generative AI application, they typically post a question or prompt to the system. At first glance, this may seem like a simple request-response mechanism, but behind the scenes, a complex orchestration of databases and AI models takes place to deliver accurate, context-aware, and relevant responses.
In this tech blog post, we’ll explore how databases play a crucial role in enhancing Generative AI applications by providing different types of contextual data that shape the final response. Below is an overview of how databases are used at different steps of a GenAI interaction.
How Databases Support the User’s Critical Path in GenAI Applications.
Here is a high-level workflow of a GenAI Application.
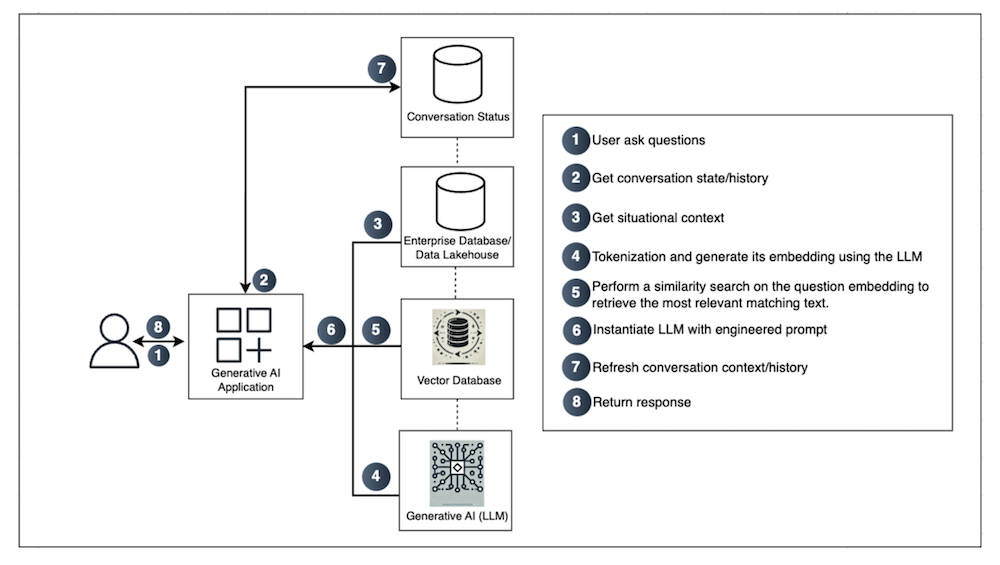
Step 1: User Asks Questions
The user initiates an interaction by submitting a query, request, or instruction to the GenAI application. This can range from simple questions to more complex tasks requiring in-depth analysis or content generation. The system captures this input and sets the stage for subsequent steps, ensuring it has a clear starting point for generating a relevant, context-aware response.
Database Role:
At this point, no direct database interaction is strictly required however, the question itself will later be stored or logged for future reference and to maintain conversation continuity. Typically, the application logs the user’s query in a database for potential auditing, analytics, or future reference. If user or session data is required at this point such as user authentication or preferences then the system may query a relational or key-value store to validate or personalize the request before moving to the next steps.
Step 2: Understanding User Interaction: Query Processing & Contextual Data Retrieval
The user submits a query to the Generative AI application, as soon as the user asks a question, the application loads a relevant prompt template. This template engineering process enhances the original question by adding additional context, ensuring the Large Language Model (LLM) produces a more accurate and relevant output.
Conversational Context (Maintaining Chat History) refers to the process of preserving and managing all previous interactions between the user and the system. This includes user queries, the system’s responses, and any relevant metadata or context. By storing and referencing this historical data in an enterprise database or data Lakehouse application can provide more coherent and personalized responses in subsequent interactions. Essentially, it enables the AI to “remember” what was previously discussed, thereby improving continuity and user experience in a conversational setting.
Database Role:
Since LLMs do not retain memory, the system stores previous user interactions in a database.
This ensures continuity in conversations, making the AI responses more coherent and contextually relevant over multiple interactions.
Enterprise Database / Data Lakehouse: Stores long-term conversation data or user session logs. When the application needs the historical context such as the user’s previous questions, system instructions, or any relevant session metadata it queries this database.
Why It Matters:
Persisting conversation data ensures the application can reference past interactions, enabling more coherent, context-aware responses.
Step 3: Context Enrichment & Knowledge Retrieval
Large Language Models (LLMs) are inherently stateless, treating each query as if it were their first. They lack any built-in mechanism to recall previous interactions or shared information, making an external data store indispensable for preserving context. Databases fill this need by retaining conversation history, user profiles, and supplementary knowledge—ultimately enriching the AI’s ability to generate coherent, context-aware responses.
Situational Context (User Profile & Operational Data)
This involves gathering any additional information the system may need to provide a well-informed response. Examples include user profile details (such as preferences or history), operational data (like current system status or relevant business metrics), and any domain-specific knowledge. By querying an enterprise database or data Lakehouse at this stage, the application retrieves the contextual data needed to tailor responses accurately and ensure relevance.
Database Role:
- The application also needs user-specific and real-time data to generate a personalized response.
- If the system requires sub-millisecond latency, A caching service is used for fast retrieval of frequently accessed data.
- The system queries a conversation history database to retrieve past interactions and user preferences.
- If the AI application supports personalization, relational databases may fetch user-specific data to tailor responses.
Steps 4 & 5: LLM-Based Embeddings and Vector Search: From Tokenization to Semantic Retrieval
The application tokenizes the original question, converting the text into a numerical form known as embeddings. These embeddings, generated by the large language model (LLM), capture the semantic meaning of the user’s query. The embeddings serve as a representation of the question in a way that helps the system understand the underlying context, enabling more accurate and contextually relevant responses. The process of embedding generation using the LLM facilitates the transformation of raw text into meaningful, machine-readable representations essential for downstream tasks.
Semantic Context: Tokenization and Embedding Generation with the LLM
The application begins by converting the user’s query into a sequence of tokens effectively translating text into a numerical form. This process, known as embedding generation, leverages a large language model (LLM) to produce high-dimensional vector representations that capture semantic meaning. By creating these embeddings, the LLM provides a nuanced context for the user’s question, laying the groundwork for more accurate and context-aware responses.
Similarity search (Vectorized Knowledge Retrieval)
Perform a Similarity Search on the Question Embedding in the GenAI workflow. Here, the system leverages a vector database to retrieve semantically similar documents or data points by comparing the numerical embeddings generated in the previous step. This allows the application to provide contextually rich and relevant information essentially capturing the “meaning” of the user’s query rather than relying solely on keyword matches.
At this stage, all three types of contexts (conversational, situational, and semantic) are synthesized into an engineered prompt to provide the LLM with the best possible input. This enables semantic search, allowing the model to find relevant information even when the exact words differ.
Database Role:
- To enhance understanding, the AI converts the user’s query into embeddings (mathematical representations of text). Need a specialized database called vector database.
- These embeddings are then searched against a Vector Database to retrieve similar text or knowledge snippets.
- Knowledge Graphs and vector databases assist in semantic search, allowing the model to find relevant facts and documents before generating a response.
- Vector databases perform similarity searches on pre-indexed text, images, or other embeddings to find relevant context for the AI model.
- This step is essential for RAG (Retrieval-Augmented Generation), where AI models ground their responses with real-time or proprietary knowledge instead of relying solely on pre-trained data.
Understanding Vector Databases: The Engine Behind Semantic Search
A vector database is a specialized data store designed to handle high-dimensional numerical vectors often called embeddings. A vector database indexes and stores vector embeddings for fast retrieval and similarity search. In GenAI applications, these embeddings represent the semantic meaning of text, images, or other data types. By storing and indexing these embeddings, vector databases enable efficient similarity searches based on conceptual proximity rather than exact string matches.
Why Use a Vector Database for Semantic or Similarity Search?
High-Dimensional Data:
GenAI models frequently produce embeddings that can have hundreds or thousands of dimensions. Vector databases provide specialized indexes (e.g., IVF, HNSW) optimized for performing approximate nearest neighbor (ANN) searches at scale.
Semantic Matching:
Instead of matching exact keywords, vector databases identify conceptually related results even if the words differ. This is essential in scenarios where synonyms or paraphrased text must be recognized as relevant.
Low Latency at Scale:
Vector databases are built to handle large volumes of embeddings while still delivering fast query times. Traditional databases often struggle with performance when tasked with similarity searches in high-dimensional space.
Integration with GenAI Pipelines:
By storing model-generated embeddings, vector databases streamline the retrieval step in many GenAI workflows, such as retrieving semantically related documents for question answering or recommendation systems.
Why Not Use a Typical Relational or NoSQL Database?
Lack of Specialized Indexing:
Relational and many NoSQL databases are optimized for structured data lookups or key-based queries, not high-dimensional similarity searches. They do not typically support the specialized indexing structures needed for efficient ANN operations.
Performance Bottlenecks:
Attempting to store and query large numbers of embeddings in a standard database can lead to high latency and resource usage, as these systems are not designed for vector-based lookups.
Limited Query Capabilities:
While you can force a relational or NoSQL database to store embeddings, you’d still need an external library or application logic to perform similarity searches. This approach is often cumbersome, less efficient, and difficult to scale.
Scaling Complexities:
Vector databases are built with distributed architectures and optimized data structures specifically for scaling similarity search workloads. Adapting a relational or general-purpose NoSQL store for these tasks can become unwieldy or prohibitively expensive.
Let’s explore this vector database with an example use-case of an e-commerce store selling running shoes, where we’ll see how semantic search helps users find the perfect pair within their budget.
1. The Problem: Keyword Search vs. Semantic Search
Many e-commerce platforms rely on keyword-based search engines. While these systems can handle exact matches (e.g., “red running shoes”), they often miss nuanced queries like “comfortable sneakers under $100.” This gap leads to missed opportunities and a poor user experience.
Why It Matters
- Enhanced User Satisfaction: Users find products that truly match their intent.
- Improved Conversions: More relevant results lead to higher purchase rates.
2. Sample Inventory Data
Consider a running shoe inventory. For simplicity, each product is represented by a 2D vector embedding (real embeddings often have hundreds of dimensions). Here’s our sample inventory in tabular form:

3. User Query
A user visits the e-commerce site and types: “I need comfortable running shoes under $100.”
Then a text embedding model (like Sentence-BERT) converts this query into a 2D embedding:

4. Vector Database Search
Instead of relying on keyword matching, we store the product embeddings in a vector database (such as Milvus, Pinecone, or Vespa). When the user submits the query:
- The application generates the query embedding [3.0, 2.7].
- The vector database performs a nearest neighbor search to find the most semantically similar products.
- Metadata filters (e.g., “under $100”) are applied to ensure only budget-friendly items are returned.
A simplified flow diagram illustrates the process:

5. Distance Calculations (Euclidean)
To determine the similarity between the query and each product, we use Euclidean distance, which is the straight-line distance between two points:

Calculated distances from the query embedding [3.0, 2.7] to each product are as follows:

Reebok Floatride is the closest match with a distance of 0.22, and it also meets the price criteria (under $100).
6. Euclidean Distance Visualization
Visualize the embeddings on a 2D plane:

7. The Result
After applying the similarity search and filtering by price:
Top Recommendation: Reebok Floatride (Distance = 0.22, Price = $90)
Runner-Up: ASICS Gel-Kayano (Distance = 0.58, Price = $110)
Other products either fall short in semantic relevance or exceed the budget.
The vector database delivers these results quickly, ensuring that even subtle nuances in user intent are matched with the most appropriate product.
Key Takeaways
Semantic vs. Keyword:
By converting text into embeddings, the system captures the true meaning behind queries and product descriptions, not just exact string matches.
Vector Databases:
Designed to store and query high-dimensional vectors, they provide efficient and scalable semantic search capabilities.
Hybrid Queries:
Combining semantic search with metadata filters (such as price) yields highly relevant and user-specific recommendations.
Visualization and Intuition:
Using Euclidean distance in a 2D plot helps illustrate how semantic similarity is determined, making the concept more accessible.
Putting all these steps together, we start by recognizing the limitations of keyword-based searches, which often fail to capture the user’s true intent. We then prepare our data by converting product descriptions into vector embeddings using a language model, ensuring each item’s semantic attributes are preserved. These embeddings are stored in a vector database, specifically designed for efficient similarity searches on high-dimensional data. When a user submits a query, we generate an embedding for that query and perform a nearest neighbor lookup against our stored product vectors. Next, we refine the results by applying any necessary metadata filters such as price or brand and rank them based on their computed distance or similarity scores. Visualizing the data in a 2D plot (for demonstration purposes) helps illustrate how these distances translate into meaningful matches. Ultimately, the system delivers contextually relevant product recommendations that not only match the user’s stated preferences but also account for subtle nuances, creating a more intuitive and effective search experience.
Tip! Vector indexing for better performance
To optimize similarity searches, leverage specialized indexing structures such as IVF, HNSW, or PQ-based approaches. These indexes enable the vector database to quickly narrow down candidate vectors, significantly reducing query times while maintaining high accuracy even at scale.
Step 6: AI Model Execution & Prompt Engineering
In this step, the application constructs a carefully engineered prompt by integrating the user’s query, relevant context retrieved from prior interactions, and any auxiliary knowledge necessary to enhance the response. This comprehensive prompt is then passed to the large language model, which synthesizes the aggregated information to generate a contextually accurate and coherent answer. By leveraging both the user’s question and the retrieved context, the LLM is able to provide a tailored, informative response that directly addresses the user’s needs.
Database Role:
- No direct database query happens at this step, but previously retrieved data ensures that the AI model generates a well-informed response.
- In some applications, embeddings generated at this stage are also stored in a vector database, streamlining future similarity searches and ensuring the LLM has immediate access to contextually relevant information for subsequent prompts.
Step 7: Updating Conversation State & Storing User Interactions
After the large language model generates a response, the application must update its records to reflect the latest exchange. This involves capturing the user’s question, the LLM’s response, and any relevant metadata such as timestamps, user identifiers, or session IDs. By preserving these details, the system maintains a comprehensive conversation history, which can be used for future context retrieval, analytics, and model improvements.
Database Role:
- A Key-Value or Document logs the user query, AI-generated response, and metadata (timestamps, feedback, etc.).
- In enterprise settings, structured responses may be logged in a relational database for future audits and analytics.
Step 8: Response Generation & Delivery
Once the large language model (LLM) has produced its output, the system finalizes and delivers the response to the user. This stage can involve several sub-processes:
Post-Processing and Formatting:
- The raw LLM output may be refined or formatted according to the application’s requirements (e.g., ensuring consistency with UI guidelines or applying a content filter to remove sensitive data).
- Additional metadata, such as response confidence scores or relevant references, can be appended for user clarity or internal logging.
Delivery Mechanism:
- The response is then sent through the appropriate communication channel such as a web interface, mobile application, or API endpoint to reach the user.
- In some cases, the system may adapt the presentation style based on the user’s device or preferences (e.g., text-only versus rich media).
Logging and Analytics:
- Simultaneously, the system may log details of the interaction like response time, content, or user feedback in a database for performance monitoring and future analysis.
- These records enable developers to assess the LLM’s effectiveness, detect issues, and iteratively refine prompts or model parameters.
By handling the final output with care, the application ensures users receive a coherent, context-aware answer while also capturing essential data for continuous improvement.
Database Role:
- If the system includes caching mechanisms, frequently used responses may be fetched from a low-latency database to optimize performance.
- The system may also use historical user interactions to refine responses over time via continuous learning and fine-tuning.
By understanding the unique characteristics of conversational, situational, and semantic contexts in GenAI applications helps ensure the right database is used for each type of data, optimizing performance and scalability. By selecting the most appropriate database for each context, applications can achieve faster query responses, more relevant results, and improved overall efficiency in managing diverse data types. This approach brings value by aligning database capabilities with the specific needs of the context, resulting in more accurate, personalized, and context-aware user experiences.
Comparing these context types clarifies their distinct data requirements and retrieval patterns, guiding more precise database selection. By aligning each context with a fitting storage solution, teams can achieve better performance, scalability, and reliability. Ultimately, this approach maximizes the quality and speed of GenAI responses, ensuring they are both contextually rich and efficient.
Below is a comparative table illustrating conversational context, situational context, and semantic context in GenAI applications, along with the most suitable database types, the rationale behind these choices with open-source examples.

Conclusion
In conclusion, by leveraging the distinct power of each context conversational, situational, and semantic GenAI applications can deliver responses that are both relevant and intuitive. Each context type requires specialized database solutions, ensuring not only the accurate storage and retrieval of information but also the ability to process data at scale. As we’ve seen, integrating the right combination of relational, document, and vector databases for each use case enables AI systems to offer more refined and contextually aware interactions. This strategic approach enhances the overall user experience, making AI-driven applications smarter, faster, and more reliable for end-users.
In conclusion, each type of context conversational, situational, and semantic plays a unique role in delivering comprehensive, accurate responses within GenAI applications. By leveraging the appropriate database solutions for each context, AI systems can combine real-time conversation logs, external domain data, and vectorized semantic knowledge into a cohesive and responsive experience. As we turn our attention to semantic context, we’ll see how vector databases and similarity searches bring deeper meaning to user queries, further enhancing the quality and relevance of the AI’s outputs.
About the Author
 Santosh Bhupathi is a seasoned Solutions Architect with over 15 years of experience in database engineering, cloud modernization, and AI-driven application design. He is a thought leader in scalable cloud architectures and purpose-built databases. Santosh actively contributes to the tech community through technical blogs, whitepapers, and conference presentations. His recent work explores the integration of generative AI with cloud-native data systems, including the use of vector databases, Retrieval-Augmented Generation (RAG), and graph-based reasoning models. He is also a peer reviewer, speaker, and judge for multiple global tech award platforms.
Santosh Bhupathi is a seasoned Solutions Architect with over 15 years of experience in database engineering, cloud modernization, and AI-driven application design. He is a thought leader in scalable cloud architectures and purpose-built databases. Santosh actively contributes to the tech community through technical blogs, whitepapers, and conference presentations. His recent work explores the integration of generative AI with cloud-native data systems, including the use of vector databases, Retrieval-Augmented Generation (RAG), and graph-based reasoning models. He is also a peer reviewer, speaker, and judge for multiple global tech award platforms.
Disclaimer: The author is completely responsible for the content of this article. The opinions expressed are their own and do not represent IEEE’s position nor that of the Computer Society nor its Leadership.